Testautomatisierung ist heute ein unverzichtbarer Bestandteil moderner Softwareentwicklung. Besonders in agilen Projekten, in denen Features kontinuierlich erweitert und angepasst werden, kann das manuelle Erstellen von Testfällen schnell zeitaufwendig und monoton werden. Häufig liegen die Anforderungen bereits in Jira-Tickets vor, doch die Überführung in ausführbare Tests erfordert wiederkehrende, mühsame Arbeit.
In diesem Tutorial zeige ich dir, wie du mithilfe von OpenAI Jira-Tickets automatisch in Gherkin-Features umwandeln kannst. Diese Gherkin-Features lassen sich direkt als Grundlage für automatisierte Tests verwenden – konsistent, wiederholbar und ohne das lästige manuelle Schreiben von Szenarien.
In einem Folge-Tutorial in den kommenden Wochen werde ich Schritt für Schritt demonstrieren, wie du die generierten Gherkin-Features direkt in Playwright-Testskripte überführst und so der komplette Testworkflow automatisiert werden kann. Sei gespannt!
Schritt 1 – Voraussetzungen
Bevor wir richtig loslegen, solltest du sicherstellen, dass dein System für die Testautomatisierung bereit ist. Dazu gehören einige grundlegende Tools und Accounts, die wir im Verlauf des Tutorials benötigen werden:
-
Node.js (v20.x oder höher empfohlen) – Node.js ist die Basis für unser Playwright-Projekt. Damit kannst du JavaScript-Code außerhalb des Browsers ausführen und automatisierte Tests steuern.
-
Playwright – Das Framework, mit dem wir unsere Tests auf verschiedenen Browsern zuverlässig ausführen. Es bietet alles, was man für moderne End-to-End-Tests benötigt.
-
Jira-Account mit API-Token – Wir werden die Jira-REST-API nutzen, um Tickets automatisiert auszulesen. Dein API-Token erlaubt es uns, sicher auf die Daten zuzugreifen.
-
OpenAI API-Key – Damit verbinden wir die KI, die aus deinen Jira-Tickets automatisch Gherkin-Features erstellt.
-
Grundkenntnisse in JavaScript – Du solltest ein Basisverständnis für JS haben, um den Code nachvollziehen und bei Bedarf anpassen zu können
Wenn Node.js noch nicht auf deinem Rechner installiert ist, findest du eine Schritt-für-Schritt-Anleitung auf nodejs.org. Auch die Installation von Playwright ist unkompliziert und wird im nächsten Schritt erklärt.
Schritt 2 – Jira-Ticket vorbereiten
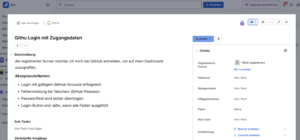
Unser Ausgangspunkt ist ein Jira-Ticket, das den Testfall beschreibt. Dabei ist es wichtig, dass das Ticket klar formuliert ist – insbesondere die Summary und die Beschreibung.
-
Summary: Kurzer Titel des Tickets, z. B.
GitHub Login -
Beschreibung: Ausführliche Beschreibung des Use-Cases, inkl. Akzeptanzkriterien
Beispiel für ein Jira-Ticket:
Schritt 3 – Playwright-Projekt aufsetzen
Falls du noch kein Playwright-Projekt angelegt hast, ist jetzt der perfekte Zeitpunkt dafür. Öffne dazu dein Terminal und lege ein neues Projektverzeichnis an:
Mit diesen Befehlen hast du ein leeres Node.js-Projekt erstellt. Als Nächstes installieren wir die notwendigen Bibliotheken für Playwright, die Jira-API und die KI-Integration:
Damit hast du:
-
Playwright für das Test-Framework und die Browsersteuerung
-
Axios für die Jira-API-Kommunikation
-
Dotenv für das Einlesen von Umgebungsvariablen
-
OpenAI für die KI-generierten Gherkin-Features
… installiert und die Playwright-Browser eingerichtet.
Es kann also losgehen : – )
Typisch für Playwright: Nach der Installation legt das Framework standardmäßig eine Datei example.spec.js im Projekt an, die als erste Beispiel-Testdatei dient. Diese kannst du entweder löschen oder als Vorlage nutzen, nachfolgend werden wir unsere eigenen KI-basierten Testskripte erstellen.

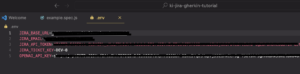
Schritt 4: .env-Datei anlegen
Um sensible Daten wie API-Keys nicht direkt im Code zu speichern, legen wir eine .env-Datei im Projekt-Root an:
Schritt 5: Jira-Client erstellen
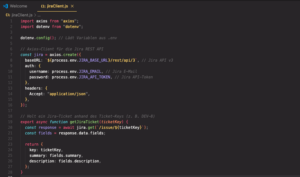
In diesem Schritt bauen wir eine kleine, gekapselte Schnittstelle zur Jira-API.
Statt Jira direkt überall im Projekt anzusprechen, erstellen wir eine eigene Axios-Instanz, die bereits alle notwendigen Informationen wie Base-URL und Authentifizierung enthält.
Die Funktion getJiraTicket reduziert die sehr umfangreiche Jira-Antwort bewusst auf das Wesentliche: Ticket-Key, Summary und Description. Genau diese Informationen benötigen wir später, um daraus mithilfe von KI automatisiert Gherkin-Szenarien zu generieren.
Schritt 6: Jira-Beschreibung für die KI aufbereiten
Jira speichert Ticket-Beschreibungen intern nicht als einfachen Text, sondern im sogenannten Atlassian Document Format (ADF).
Dieses Format ist stark verschachtelt und für KI-Modelle schwer nutzbar.
Damit wir die Ticket-Beschreibung später sinnvoll an OpenAI übergeben können, wandeln wir sie in Plain Text um.
Dafür erstellen wir einen kleinen Helper, der den Text rekursiv aus der Jira-Struktur extrahiert.

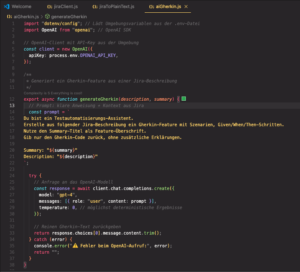
Schritt 7: Gherkin-Szenarien mit KI generieren
Nachdem wir die Jira-Beschreibung erfolgreich in lesbaren Plain Text umgewandelt haben, folgt nun der zentrale Schritt des Tutorials:
Wir übergeben diesen Text an eine KI und lassen daraus automatisch ein Gherkin-Feature erzeugen.
Die Idee dahinter:
Statt manuell Szenarien zu formulieren, nutzen wir ein Sprachmodell, das Anforderungen versteht und sie in strukturierte Given/When/Then-Schritte übersetzt. Dafür kapseln wir den OpenAI-Zugriff in eine eigene Funktion – übersichtlich, wiederverwendbar und leicht erweiterbar.
Schritt 8: Alles zusammenführen – vom Jira-Ticket zur Gherkin-Datei
In den vorherigen Schritten haben wir die einzelnen Bausteine vorbereitet:
Wir können Jira-Tickets auslesen, ihre Beschreibung in verständlichen Text umwandeln und mithilfe einer KI daraus Gherkin-Szenarien generieren.
In diesem Schritt führen wir nun alles zusammen.
Ziel ist es, einen automatisierten Ablauf zu schaffen, der:
-
ein Jira-Ticket anhand seiner Ticket-ID lädt
-
die Beschreibung für die KI aufbereitet
-
daraus automatisch ein Gherkin-Feature erzeugt
-
dieses Feature direkt als
.feature-Datei im Projekt speichert
Damit entsteht aus einem Jira-Ticket mit nur einem einzigen Testlauf eine konkrete, versionierbare Testgrundlage, die später direkt für Cucumber oder Playwright weiterverwendet werden kann.
Das folgende Playwright-Testskript übernimmt genau diese Aufgabe. Es dient dabei weniger als klassischer UI-Test, sondern vielmehr als Automatisierungs-Job, der Anforderungen in ausführbare Testartefakte übersetzt.
Im nächsten Codebeispiel schauen wir uns diesen Prozess Schritt für Schritt an:

Schritt 9: Test ausführen
Nachdem alle Bausteine miteinander verbunden sind, können wir den Prozess nun erstmals vollständig ausführen.
Starte den Test direkt über Playwright mit folgendem Befehl:

Playwright führt nun keinen klassischen UI-Test, sondern einen technischen Test aus, der:
-
das definierte Jira-Ticket per API abruft
-
die Ticketbeschreibung in Klartext umwandelt
-
die Daten an die KI weitergibt
-
ein vollständiges Gherkin-Feature generiert
-
dieses Feature automatisch als
.feature-Datei im Projekt speichert
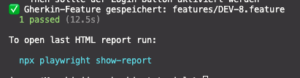
Am Ende liegt im Ordner features/ eine Datei wie:
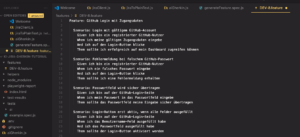
Diese Datei stellt bereits ein valide formuliertes Gherkin-Feature dar und kann ohne weitere Anpassungen für BDD-basierte Tests verwendet werden.
Fazit: Von Anforderungen zu Testartefakten – vollautomatisch
Mit diesem Tutorial haben wir einen wichtigen Schritt in Richtung intelligenter Testautomatisierung gemacht.
Statt Anforderungen manuell zu interpretieren und Testfälle von Hand zu schreiben, hast du nun:
-
Jira-Tickets direkt als Input genutzt
-
KI eingesetzt, um konsistente Testlogik zu erzeugen
-
Gherkin als sauberes, fachlich lesbares Zwischenformat verwendet
-
einen reproduzierbaren Prozess geschaffen, der sich in reale Projekte integrieren lässt
Besonders wertvoll ist dieser Ansatz in agilen Teams, in denen sich Anforderungen häufig ändern und Testfälle kontinuierlich angepasst werden müssen.
Teil 2 – Von Gherkin zu ausführbaren Playwright-Tests (mit KI)
Im nächsten Tutorial gehen wir den entscheidenden Schritt weiter:
Von Gherkin zu Cucumber-Tests mit Playwright – erneut KI-gestützt
Konkret werden wir:
-
die generierten
.feature-Dateien mit Cucumber ausführen -
automatisch Step Definitions aus Gherkin erzeugen
-
KI nutzen, um Gherkin-Schritte in konkrete Playwright-Aktionen zu übersetzen
-
echte End-to-End-Tests entstehen lassen, die wartbar und nachvollziehbar sind
Damit schließen wir den Kreis von:
Jira-Anforderung → Gherkin → Cucumber → Playwright-Test