Selenium gilt als alter Hase der Testautomatisierung – besonders im Enterprise-Umfeld. Viele Testerinnen und Tester kennen jedoch dasselbe Problem: Tests scheitern nicht wegen fachlicher Fehler, sondern weil Locators brechen.
Ein kleines UI-Refactoring, eine neue CSS-Klasse – und plötzlich schlagen mehrere Tests fehl. Nicht, weil die Anwendung falsch funktioniert, sondern weil der Test zu stark an die DOM-Struktur gekoppelt ist.
In diesem Beitrag möchte ich Dir zeigen, wie man dieses Problem nicht mit noch mehr XPaths, sondern mit Künstlicher Intelligenz angehen. bzw. verbessern kann – konkret mit Selenium und Cohere in Python, am Beispiel des GitHub-Logins.
Das eigentliche Problem: Technik vs. Verhalten
Klassische Selenium-Tests vermischen oft drei Dinge:
- fachliche Testabsicht
- technische Umsetzung
- konkrete DOM-Struktur
Das führt dazu, dass Tests eher beschreiben, wie etwas umgesetzt ist, statt was eigentlich geprüft werden soll. Gerade bei modernen Webanwendungen mit dynamischem DOM wird das schnell zum Wartungsproblem.
Warum GitHub ein gutes Beispiel ist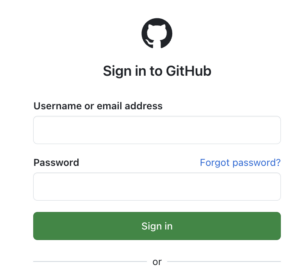
Für dieses Beispiel nutze ich bewusst die GitHub-Login-Seite:
https://github.com/login
GitHub ist ein professionelles Frontend mit:
- nicht-trivialer DOM-Struktur
- dynamischen Fehlermeldungen
- regelmäßigen kleinen UI-Änderungen
Perfekt, um die Problematik fragiler Locator-Strategien realistisch zu demonstrieren.
Der klassische Selenium-Test – fragil
Ein typisches Szenario:
- Login-Seite öffnen
- Ungültige Zugangsdaten eingeben
- Prüfen, ob eine Fehlermeldung angezeigt wird
// Suchen des Benutzernamen-Eingabefeldes auf der Login-Seite
WebElement usernameInput = driver.findElement(
By.xpath("//div[@id='login']/div[4]/form/input[1]")
);
usernameInput.sendKeys("wronguser@example.com");
.....
// Suchen des "Sign In"-Buttons auf der Login-Seite und klicken des Buttons
WebElement signInButton = driver.findElement(
By.xpath("//div[@id='login']/div[4]/form/div/input[12]")
);
signInButton.click();
// Suchen der Fehlermeldung, die angezeigt wird, wenn Login fehlschlägt
WebElement errorMessage = driver.findElement(
By.xpath("//div[contains(@class,'flash-error')]")
);
// Überprüfen, ob die Fehlermeldung angezeigt wird
assertTrue(errorMessage.isDisplayed());
Probleme des Ansatzes:
- schwer lesbar
- stark DOM-abhängig
- extrem anfällig für kleine UI-Änderungen
Willkommen in der klassischen XPath-Hölle. Und mir ist natürlich bewusst, dass man hier die stabilen IDs des GitHub-Login-Seite verwenden kann – das würde den Test robust machen. Aber nicht jede Anwendung bietet solche IDs. Gerade bei alten UIs wird die XPath-Hölle schnell Realität. Genau hier kann KI helfen, die Testabsicht unabhängig von der DOM-Struktur zu übersetzen.
Was wir fachlich eigentlich testen wollen
Abstrahiert bleibt etwas sehr Einfaches:
- Ein Nutzer gibt ungültige Login-Daten ein
- Eine Fehlermeldung wird angezeigt
In natürlicher Sprache:
- „Fill in the login form with invalid credentials“
- „Verify that an error message is shown“
Genau hier kann KI sinnvoll unterstützen.
Selenium + Cohere: Natürliche Sprache statt DOM-Details
Der Ansatz kombiniert:
- Selenium für die Browsersteuerung
- Cohere als Sprachmodell, um natürliche Sprache in CSS-Selectoren zu übersetzen
Wichtig:
Die KI ersetzt Selenium nicht.
Sie dient lediglich als Übersetzungsschicht zwischen Testabsicht und technischer Umsetzung.
Beispiel: KI-gestützter Login-Test
Der folgende Code zeigt nicht das komplette Skript, sondern nur die entscheidenden Bausteine, die den KI-Ansatz ausmachen.
1. Selenium liefert der KI den relevanten Kontext

Statt den kompletten DOM zu analysieren, wird nur das Login-Formular extrahiert.
So arbeitet die KI mit einem klaren, semantisch fokussierten Kontext.
2. Fachliche Anweisungen definieren die Rollen
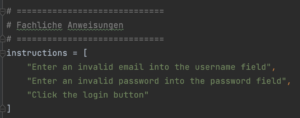
Die fachlichen Anweisungen helfen der KI, die richtige Rolle für jedes Element zu erkennen – also Username-Feld, Passwort-Feld oder Login-Button. Sie beschreiben die Testabsicht, nicht die technischen Details der Eingabe. In einfachen Fällen mit eindeutigen IDs könnte man diesen Schritt auch weglassen – er ist aber besonders bei komplexen oder fremden UIs sinnvoll.
3. Die KI liefert Rollen → CSS-Selectoren
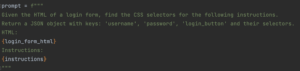
Die Keys (username, password, login_button) sind logische Rollen.
Die Values, die die KI zurückliefert, sind konkrete CSS-Selectoren.
Beispiel:
{
"username": "#login_field",
"password": "#password",
"login_button": "input[type='submit']"
}
4. Selenium führt den Test aus
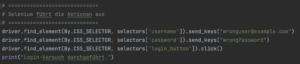
Selenium bleibt vollständig verantwortlich für:
- Testdaten
- Aktionen
- Ablaufkontrolle
Die KI hilft nur beim Finden der richtigen Elemente.
Vorteile dieses Ansatzes
| Klassischer Selenium-Test | Selenium + KI |
|---|---|
| Fragile XPaths | Kontextbasierte Interaktion |
| Stark DOM-abhängig | Semantisch orientiert |
| Schwer lesbar | Nahe an natürlicher Sprache |
| Hoher Wartungsaufwand | Geringerer Wartungsaufwand |
Hinweis:
Die KI analysiert nur das relevante Formular, nicht den kompletten DOM.
Sie orientiert sich an sichtbaren Labels, Platzhaltern, Rollen und Kontext.
Ausgabe der KI: Gefundene CSS-Selectoren
Nachdem die KI die Rollen (username, password, login_button) analysiert hat, liefert sie konkrete CSS-Selectoren. Nun können wir die Eingabefelder der Loginmaske entsprechend mit den fehlerhaften Credentials füllen und auf den Sign-In-Button klicken. Das Ergebnis:
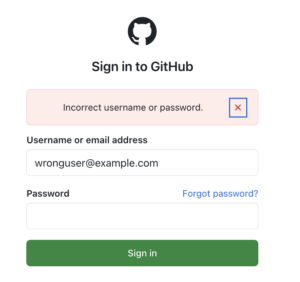
So sieht die Konsolenausgabe aus:
Abschließende Worte
Selenium ist nicht das Problem – fragile Locators sind es. Durch die Kombination von Selenium mit einem Sprachmodell wie Cohere lassen sich Tests:
- robuster formulieren
- wartungsärmer gestalten
- näher an der fachlichen Realität beschreiben
Gerade im Enterprise-Umfeld ist das kein Hype, sondern ein pragmatischer Schritt zu stabilerer Testautomatisierung.